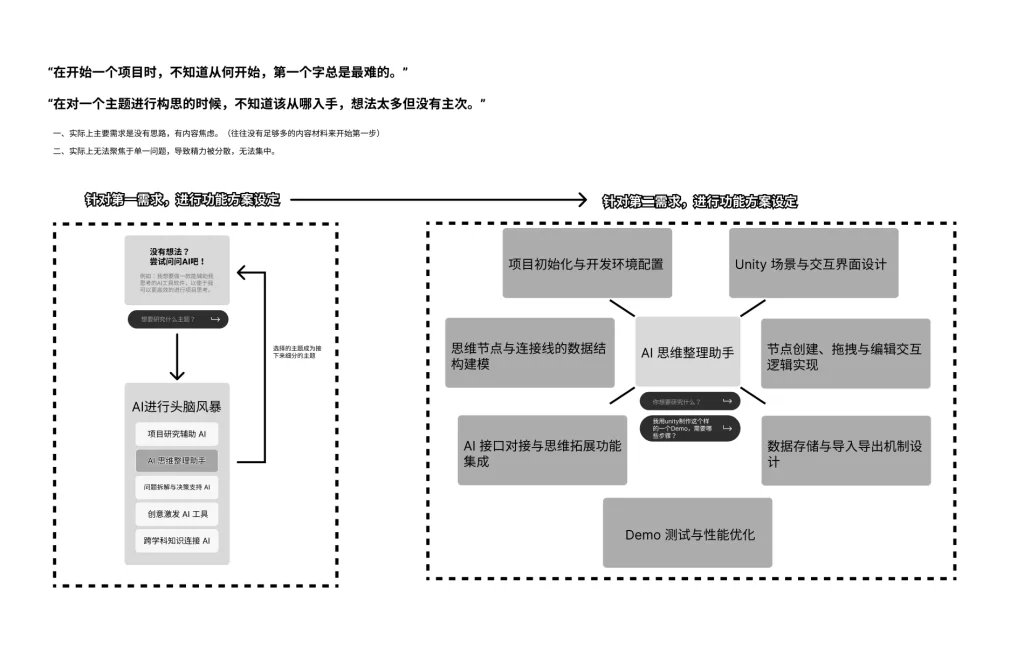
该项目是在北京通用人工智能研究院,与Rich合作设计开发的基于AR元霓设备,使用Unity3D引擎架构的AI智能语音助手项目。
一、项目构思
项目灵感源于某地区考古博物馆AR文旅项目的前期策划方案——馆方希望能有个一直跟随用户的AR助手,具备全程跟随、辅助引导、实时解答等功能。由于特殊原因,AR文旅项目搁置,但该灵感在内部继续孵化,进而衍生出此项目。
该项目在初期就已经确定了其大致方向——即一个具备实时跟随、语音问答以及图像识别的AR智能体。
基于以上内容,在功能实现路径上,考虑到小体量应用,本地部署服务存在维护成本大、部署周期长等风险,故而采取了Unity3D 搭建逻辑框架 + api服务调用这种常用的实现路径。
二、项目设计
整体框架:
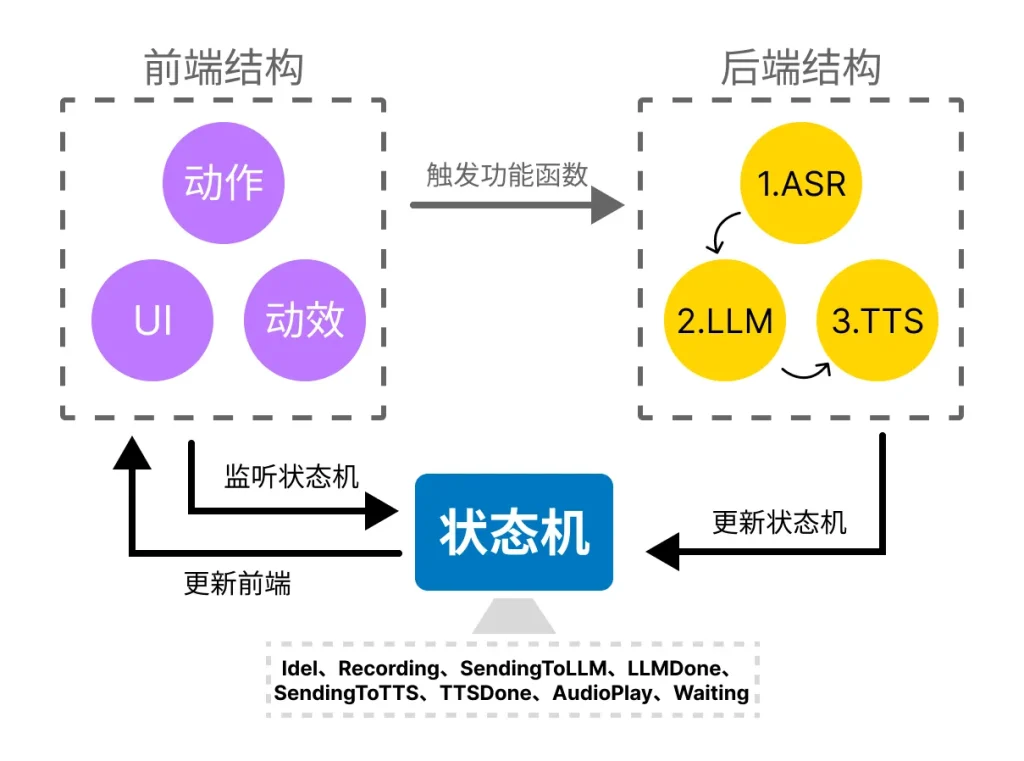
该项目中核心内容为智能体机器人实体,它涉及到跟随、聆听问题、回答问题等功能。这些功能之间的切换即是状态的切换,而这些状态不能与其他状态相互叠加。
对此,我们设计了基于状态机控制前端与后端的逻辑结构。
例如:
初始为 idle 闲置状态,当用户触发提问功能时,状态机改变为 Recording 聆听记录语音,同时状态机告诉后端ASR模块可以开始处理语音Chunk,以及告诉前端UI可以更新ASR传回的文本内容。
而当用户说完并发送时,状态机改变为SendingToLLM,从该阶段开始,用户就不能再次进行语音发送,需要等待这条任务完成后,状态回归idle时,才能再次提问。
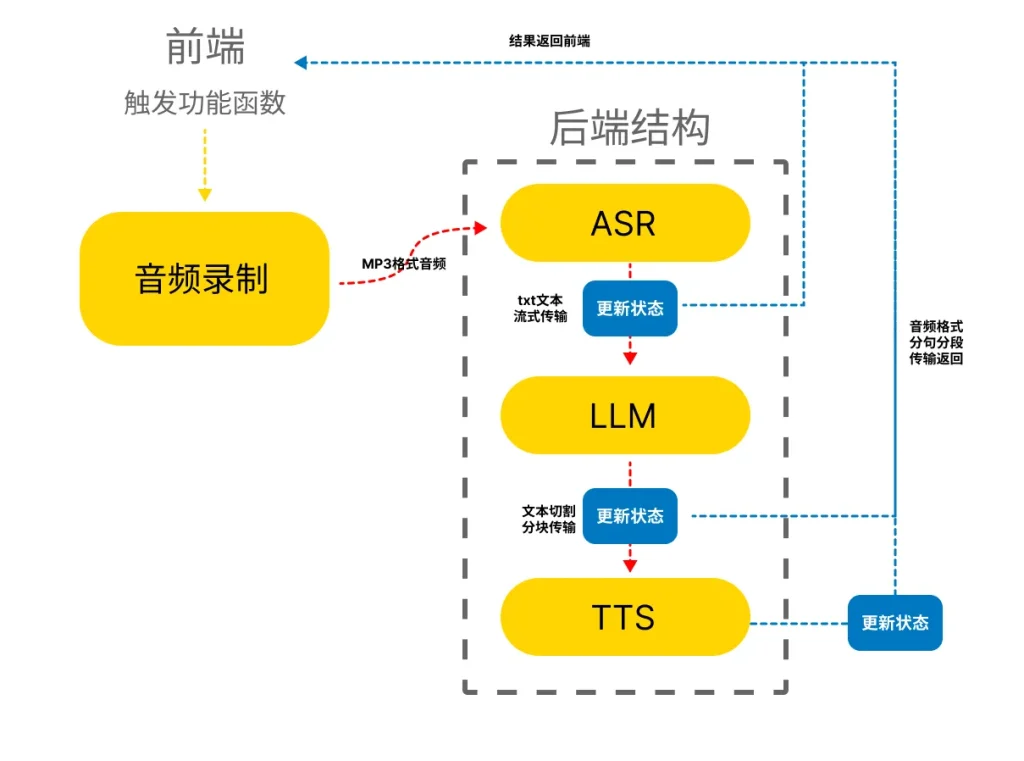
Api流程:
在可行性测试阶段,数据处理方式为队列式的处理方式,完成一个再进行第二个。测试时发现,该方法十分耗时,等待时间非常长。
在多次迭代后,采用了流式的处理方式,即ASR(语音转文字)时,随着语音的输入,文字在流式的传回客户端,并储存在Massage容器中,当触发发送条件,该容器的内容会立刻传入LLM中,LLM在处理结束后同样流式的传入LLM_Content容器中,此时通过文本分割方法,将传入的LLM_Content内容分割为单句,以队列的形式存储,并发送到TTS(文本转语音)中,返回的内容会被转换为Audio Clip格式,发送到Unity Audio Source中播放。
三、项目实现
代码逻辑结构:
通过状态机,链接后端状态和前端状态,以达到在不同阶段,前端机器人做出不同反映。
代码实现:
全局广播,订阅者订阅该组件的广播:
//声明全局广播,用于通知所有相关组件
public event Action<E_States,string ,string> AITalkStates;状态机控制单元,每次状态更新时调用:
//状态控制单元,每个步骤变更时,广播状态给所有订阅者
public void UpdateStates(E_States e_states)
{
//检测当前状态并播报
switch (e_states)
{
case E_States.Idle:
states = "空闲";
break;
case E_States.Recording:
states = "正在录制";
break;
case E_States.SendingToLLM:
states = "正在发送至LLM";
break;
case E_States.LLMDone:
states = "LLM处理完成";
break;
case E_States.SendingToTTS:
states = "正在发送至TTS";
break;
case E_States.TTSDone:
states = "TTS处理完成";
break;
case E_States.AudioPlay:
states = "音频播放中";
break;
case E_States.Waiting:
states = "等待中...";
break;
}
text_states = e_states;//传递一个state出来公用
States?.Invoke(states);
AITalkStates?.Invoke(e_states, ask,answer);
}订阅事件后,供事件调用的接口:
/// <summary>
/// 订阅状态事件后,供事件调用的方法
/// </summary>
/// <param name="states">事件广播的状态枚举</param>
public interface ISubscribable
{
public void SubscribEvent(E_States states,string asks,string answers);
}